
Etiquetas
Cultura de seguridad, Cultura justa, Gestión de riesgos, Seguridad aérea, Técnica, TCAS, Uberlingen
No me gusta demasiado entrar en polémicas y por eso este blog no trata directamente de mi trabajo ni de temas de actualidad sino que suele buscar paralelismos entre acontecimientos presentes y otros del pasado. Eso cuando no busco algún incidente de aviación que creo que es interesante o decido simplemente escribir algo entretenido y me decido por narrar una historia de piratas. Pero hoy voy a hacer una excepción. La causa es el desgraciado accidente ferroviario en el que han muerto cerca de 80 personas.
Es lamentable que en estos casos se tienda a buscar una explicación rápida y sencilla sin aguardar a que se realice un informe de seguridad detallado e independiente. El resultado es que se busca un culpable, se le adjudica toda la responsabilidad y se finge que el sistema está bien diseñado y gestionado sin tener en cuenta que en un sistema complejo un fallo único no explica un accidente. Hace algún tiempo escribí un artículo sobre la colisión entre dos aviones sobre Überlingen en el que explicaba todos los fallos que se presentaron aquel día y cómo la prensa y el público se habían limitado a acogerse al mucho más sencillo y tranquilizador fallo humano. Mucho me temo que las cosas siguen igual.
Como no soy experto en ferrocarriles no voy a intentar un análisis, que en cualquier caso sería prematuro puesto que aún no tenemos todos los datos. Pero sí os contaré algo que puede dar un poco de luz. Hace ahora dos años yo estaba trabajando en un documento que debía presentar en una conferencia internacional y que trataba sobre la implementación de nuevos sistemas en la Gestión de Tráfico Aéreo. Una de las fuentes que empleé la obtuve de la FAA, la agencia gubernamental estadounidense que se encarga de la aviación. El documento en cuestión está disponible aquí y es una guía sobre la gestión de riesgos aplicada a la adquisición de sistemas. En la página 15 hay una tabla de la que yo hice mi propia versión para mi documento. Básicamente es lo que vemos a continuación.
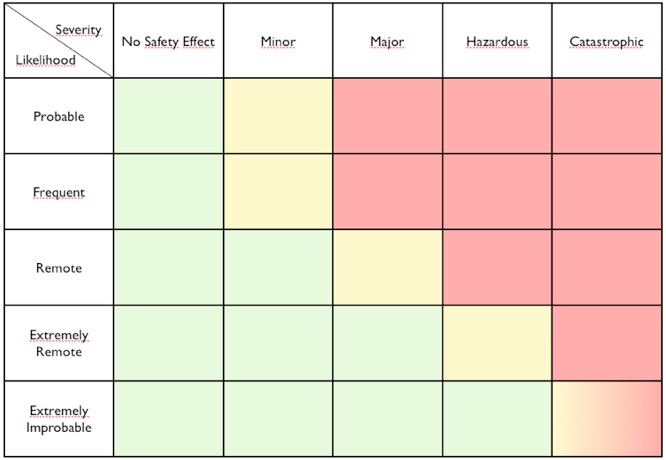 La tabla es una matriz de gestión de riesgos. Por un lado tenemos la probabilidad de que ocurra un suceso y por el otro la gravedad de las consecuencias que se pueden derivar de dicho suceso. Aunque los términos estén escritos en inglés, creo que se entiende bastante bien. Aun así la explicaré con un poco más de detalle.
La tabla es una matriz de gestión de riesgos. Por un lado tenemos la probabilidad de que ocurra un suceso y por el otro la gravedad de las consecuencias que se pueden derivar de dicho suceso. Aunque los términos estén escritos en inglés, creo que se entiende bastante bien. Aun así la explicaré con un poco más de detalle.
La probabilidad del suceso se puede dar de distintas formas, pero la más intuitiva es la frecuencia con la que se espera que se pueda repetir el evento. En nuestro caso la FAA, aplicando el concepto al control aéreo, nos da esa frecuencia tanto en una posición individual de control, como en un centro de control compuesto de muchas posiciones y también en el conjunto de todos los centros de control de Estados Unidos. Así, un suceso puede ser:
- Frecuente: puede ocurrir una vez cada 3 meses aproximadamente en una posición individual, que es como decir que ocurrirá una vez al día o una vez cada dos días en el conjunto de todos los centros que forman el sistema.
- Probable: Se calcula que ocurrirá varias veces al mes en el conjunto del sistema.
- Remoto: Se espera que ocurrirá una vez cada pocos meses en el conjunto del sistema.
- Extremadamente remoto: Se calcula que ocurrirá aproximadamente una vez cada 3 años en el conjunto del sistema.
- Extremadamente improbable: Se calcula que ocurrirá como mucho una vez cada 30 años en el conjunto del sistema.
En el caso de la gravedad del suceso tenemos una escala que va desde catastrófico (el accidente) hasta la falta de efectos en la seguridad pasando por varios estados (cuasicolisión, necesidad de maniobra evasiva basada en el sistema anticolisión TCAS, etc.)
Los colores indican si el riesgo es o no aceptable y sirven de guía para introducir novedades en el sistema. El verde es aceptable, el rojo totalmente inaceptable y el amarillo implica que se puede realizar el cambio, pero debe estar sometido a seguimiento y evaluación. Por ejemplo, introducimos un nuevo componente cuya probabilidad de fallo es muy escasa, por lo que calculamos que en un único centro de control se produciría el fallo una vez cada 10 años o más y eso quiere decir más o menos una vez cada 3 años en el conjunto de todos los centros. Eso es un suceso extremadamente remoto. Si ese fallo implicara que podríamos tener un incidente severo, el color amarillo indica que sí que podemos introducir el cambio gracias a lo improbable de la situación, aunque siempre sometiéndolo a seguimiento; pero si consideráramos como muy posible que un fallo en ese componente diera lugar a un accidente el color rojo avisa de que no podemos introducirlo.
Veamos un ejemplo en el que aplicaremos la tabla a un motor de aviación. El fabricante nos dará todos sus parámetros, por lo que sabremos la probabilidad de que haya una pérdida de potencia. Lo peor que puede ocurrir es que ese caso se dé justo en el momento en el que el avión está en carrera de despegue y rotando, es decir, empezando a levantar el morro. Como las normas obligan a que el avión sea capaz de despegar aunque tenga un motor parado el caso no sería catastrófico, aunque sí muy grave. Si la fiabilidad es tal que el caso es extremadamente improbable la casilla es verde y podemos usar ese motor, pero si nuestro motor no es tan fiable y el caso entra en lo extremadamente remoto la casilla amarilla implica que tendremos que someterlo a vigilancia: por ejemplo obligando a guardar en cada vuelo un registro de determinados parámetros, para su análisis posterior. Si el motor es tan poco fiable que el fallo entra en lo remoto, probable o frecuente el color rojo deja claro que su instalación es inaceptable por motivos de seguridad.
En la tabla hay una casilla peculiar, porque no es roja ni amarilla, sino una mezcla: se trata de un suceso extremadamente improbable cuya presencia implicaría un posible accidente. Esa casilla se debe tratar como amarilla, pero debe ser considerada como roja en el caso de fallos de punto único. Es decir, un sistema así es admisible con supervisión, pero no si el fallo en ese punto único provoca el accidente. Volvamos al ejemplo del motor para entenderlo mejor.
Supongamos el motor más fiable del mercado. Tal y como hemos visto su fallo daría lugar a una situación muy peligrosa, pero no necesariamente a un accidente, así que se puede utilizar sin problemas. ¿Y si el avión fuera monomotor? En ese caso tenemos que su fallo, por muy improbable que fuera, sí echaría abajo nuestro sistema (el avión). Por lo tanto consideraríamos esa casilla como roja.
Sin embargo si en lugar de un motor estuviéramos considerando instalar un TCAS (sistema anticolisión) sería cierto que su fallo puede dar lugar a un accidente, pero para ello tendrían que darse previamente otros muchos errores, puesto que el sistema sólo funciona como último recurso. La casilla en este caso sería amarilla. (Para más detalles sobre cómo funciona el TCAS recomiendo una ojeada al artículo que mencioné al principio sobre el accidente de Überlingen).
La consecuencia de esa casilla está clara: no es admisible un sistema en el que el fallo de un único componente lleve a un resultado fatal. Y eso incluye cualquier componente del sistema, también el ser humano. Porque las probabilidades de fallo del ser humano son bastante indeterminadas, pero existen: una persona puede distraerse, cometer un error, sufrir un infarto, tener una perforación de estómago, ingerir un alimento en mal estado… cualquiera de estos incidentes puede incapacitar al componente humano del sistema y por eso hay que prever su fallo y buscar la forma de compensarlo.
Volvamos ahora al origen de este artículo. Ahora sabemos que un sistema bien diseñado y gestionado no puede depender en ningún momento de uno solo de sus componentes. Por eso es tan necesaria una investigación, exhaustiva e independiente, antes de juzgar, ya que la socorrida explicación del error humano significaría a lo sumo que un componente del sistema, el humano, ha fallado ¿pero qué pasó con el resto de componentes? ¿O es que quien diseñó el sistema confiaba en que había un componente de fiabilidad infinita que jamás iba a fallar? ¿O lo diseñó correctamente, pero el sistema se había degradado previamente al fallo humano? Y en ese caso ¿por qué se dejó que el sistema siguiera funcionando como si no hubiera pasado nada?
Como vemos hay muchas preguntas que pueden implicar no sólo a la parte operativa del sistema sino también a su diseño y gestión. Demasiadas cuestiones para responder en unas pocas horas y sin un análisis detallado. En cualquier caso se echa de menos el concepto de Cultura Justa (o Cultura de Equidad), según el cual el error no debe criminalizarse, sin que esto signifique que la negligencia quede impune. Pero los modelos de seguridad y el concepto de Cultura Justa merecen un artículo aparte que prometo escribir en breve.

Ignacio sólo puedo decir: gracias ! Siempre creo que el último es insuperable…pero este es tan enriquecedor y tan ilustrativo que pasa a ser mi más favorito y corro a enviar el enlace a todas las personas a quienes quiero para que lo disfruten. Gracias, siempre me queda una sensación de tranquilidad cuando término de leer tus artículos … Incluso los de piratas! … Me encanta !
Caray, con seguidores tan entusiastas da gusto. 😉 A ver cuándo tengo tiempo y me pongo con la segunda parte.
Pues si el contenido del artículo propuesto es tan racional e interesante como este, quedo espectante y a la espera de poder disfrutarlo. Lástima que seamos tan simples que solo queramos escuchar la salida fácil. Felicidades por tu trabajo en el blog, Ignacio.
Excelente. Hago referencia a Überlingen en esta petición. https://www.change.org/es/peticiones/pedimos-la-dimisi%C3%B3n-inmediata-del-presidente-de-adif-gonzalo-ferre-molt%C3%B3
Muchas gracias por compartir tanto conocimiento
saludos